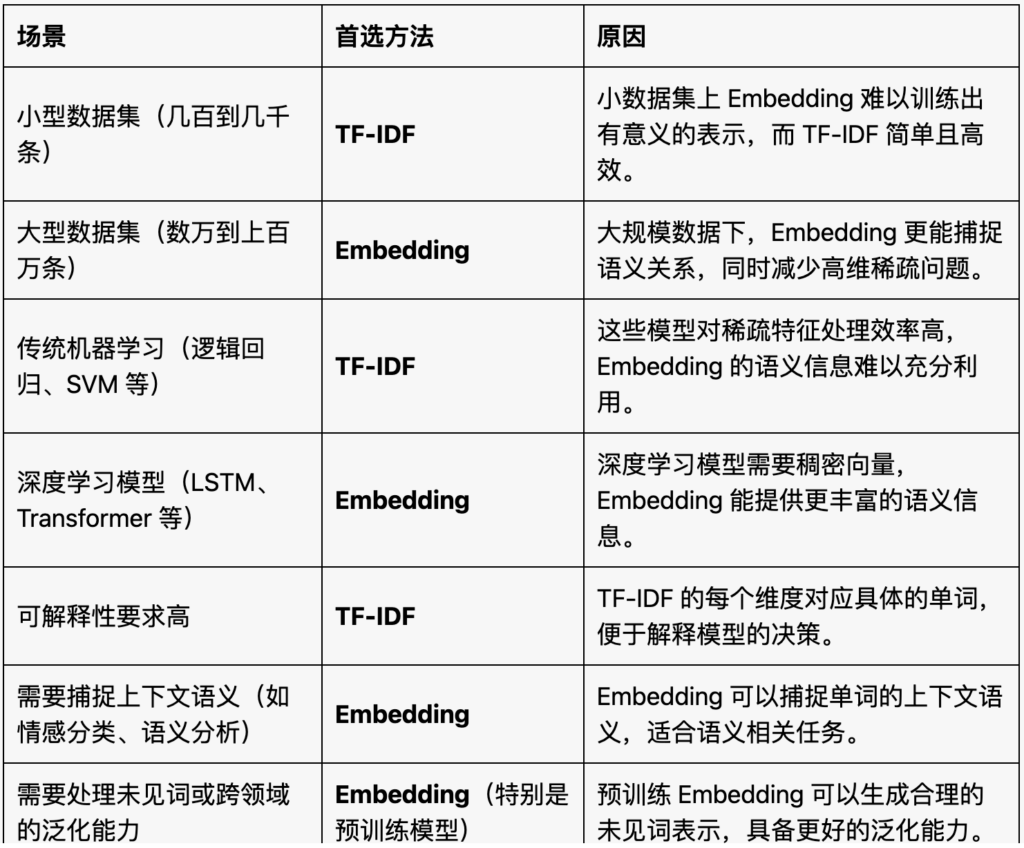
TF-IDF vs Embedding
2025年2月8日在处理文本特征时,选择 TF-IDF 或 Embedding 方法需要根据具体的场景和需求来决定。两者有不同的特点和适用场景,参考如下对比表。
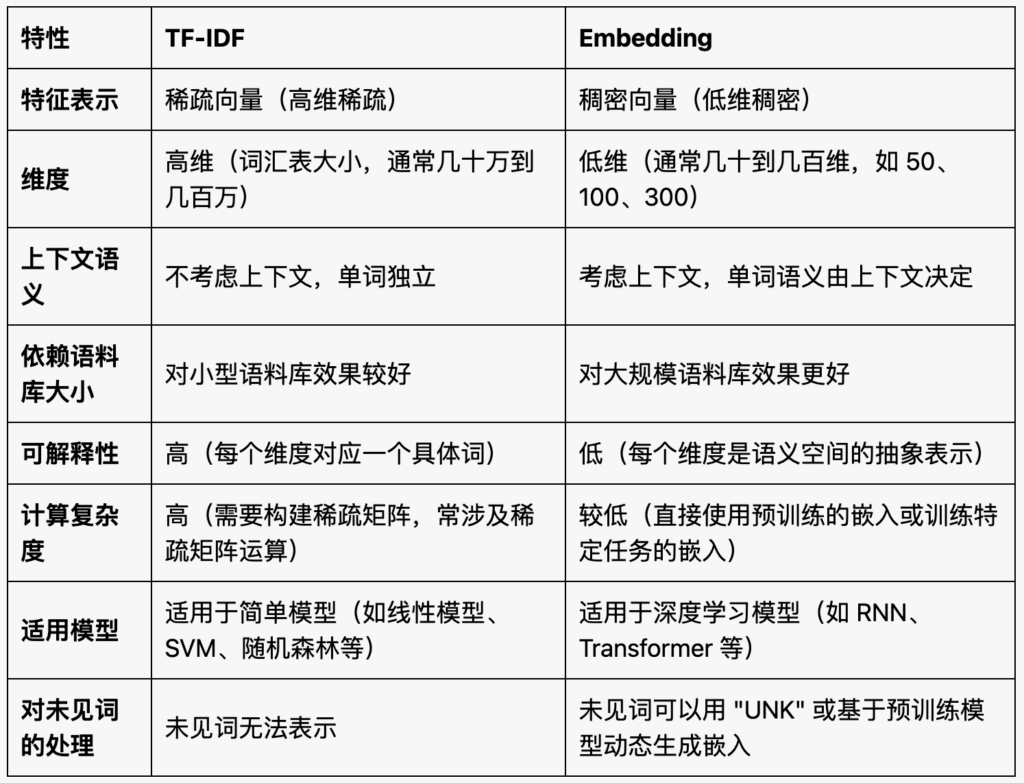
什么时候使用 TF-IDF?
1. 适合小规模数据集
- 如果你的语料库较小(例如只有几百到几千条文本),那么使用 TF-IDF 是更好的选择。
原因:在小规模数据上,TF-IDF 能够快速提取每个单词的重要性,而嵌入方法可能无法训练出有意义的语义表示。
2. 可解释性需求
- 如果需要对模型的决策过程进行解释,TF-IDF 是一个更好的选择。
原因:TF-IDF 的特征表示直接反映了词频和词的重要性,容易追踪模型对哪些词做出了决策。
3. 使用传统机器学习模型
- 如果采用的是非深度学习模型(如逻辑回归、SVM、随机森林等),TF-IDF 更加适配。
原因:这些模型对稀疏矩阵的处理更高效,而 Embedding 的语义信息通常无法被这些模型充分利用。
4. 任务对上下文的依赖较低
- 如果文本特征的上下文关系并不重要(例如关键字匹配、主题分类等任务),可以选择 TF-IDF。
原因:TF-IDF 仅关注单词的频率和重要性,不考虑上下文。
5. 数据稀疏的特征工程
- 在某些任务中,你可能需要进一步手动提取特征(如关键词统计、主题建模)。TF-IDF 提供了一种很好的稀疏特征表示形式,便于进行特征工程。
什么时候使用 Embedding?
1. 需要捕捉上下文语义
- 如果任务需要理解文本的语义(比如情感分析、问答系统、推荐系统等),Embedding 是更好的选择。
原因:Embedding 方法(尤其是基于预训练模型的动态嵌入)能捕捉单词在上下文中的语义变化,具有更强的表达能力。
2. 适合大规模数据集
- 如果你的语料库足够大(例如数万到百万条文本),Embedding 方法的效果通常比 TF-IDF 好。
原因:在大规模数据上,Embedding 方法可以更充分地学习语义关系,而 TF-IDF 可能因为稀疏性导致模型难以训练。
3. 使用深度学习模型
- 如果你计划使用深度学习模型(如 LSTM、GRU、Transformer 等),Embedding 是首选。
原因:深度学习模型通常需要稠密、低维的向量表示作为输入,而 TF-IDF 的稀疏特征在这些模型中不适用。
4. 需要泛化到新词或新任务
- 如果你的任务可能会遇到未见词(如用户生成内容中的新词),Embedding 更具优势。
原因:Embedding 方法(特别是预训练模型如 Word2Vec、GloVe、BERT 等)可以对未见词生成合理的向量表示。
5. 任务复杂、语义相关性强
- 如果任务需要理解句子或文档的复杂语义关系(如机器翻译、文本生成等),Embedding 是更好的选择。
原因:Embedding 方法通过低维向量捕捉了单词间的语义关系,而 TF-IDF 无法有效表示这些关系。
综合选择建议