提取图像特征的主流CNN模型
2025年2月20日在现代深度学习中,卷积神经网络(CNN) 是图像特征提取的核心方法。随着研究的不断进步,已经出现了许多经典且主流的 CNN 模型,能够自动提取图片特征。这些模型在多种任务(如图像分类、目标检测、语义分割)中表现出色。以下是目前主流的 CNN 模型及其特点的详细说明.
1. VGG(Visual Geometry Group)系列
- 代表模型:
- VGG16、VGG19
- 特点:
- 使用 多层 3×3 小卷积核 和 2×2 最大池化层 进行特征提取。
- 网络深度较深(16 或 19 层),但结构简单,易于理解和实现。
- 特征表达能力强,适合迁移学习。
- 不足:
- 参数量大,计算复杂度高,不适合资源受限的设备。
- 应用场景:
- 图像分类、特征提取(常用于迁移学习的特征提取器)。
2. ResNet(Residual Neural Network)系列
- 代表模型:
- ResNet18、ResNet34、ResNet50、ResNet101、ResNet152
- 特点:
- 提出了 残差结构(Residual Block),通过跳跃连接解决了深层网络中的梯度消失问题。
- 支持非常深的网络(超过 100 层),在 ImageNet 等大型数据集上表现优异。
- 结构灵活,可用于多种任务(如分类、检测、分割)。
- 不足:
- 参数量和计算量较大,但比 VGG 更高效。
- 应用场景:
- 图像分类(如 ImageNet)、目标检测(如 Faster R-CNN 的主干网络)。
3. Inception(GoogLeNet)系列
- 代表模型:
- GoogLeNet、Inception v2、Inception v3、Inception v4
- 特点:
- 提出了 Inception 模块,通过多种卷积核(1×1、3×3、5×5)并行提取特征,结合池化操作,捕获多尺度特征。
- 计算效率高,参数量小。
- Inception v3 和 v4 在原始 Inception 基础上进一步优化,并引入了更深的层。
- 不足:
- 结构复杂,难以实现和调整。
- 应用场景:
- 图像分类、特征提取、目标检测。
4. MobileNet 系列
- 代表模型:
- MobileNet v1、MobileNet v2、MobileNet v3
- 特点:
- 专为移动设备和嵌入式设备设计,轻量化,计算效率高。
- 使用 深度可分离卷积(Depthwise Separable Convolution),显著减少计算量。
- MobileNet v2 引入了 反向残差结构(Inverted Residual Block) 和 线性瓶颈,性能更优。
- MobileNet v3 结合了 神经架构搜索(NAS) 和 SE 模块,进一步优化性能。
- 不足:
- 在高精度任务上性能可能不如 ResNet 等较大模型。
- 应用场景:
- 边缘计算、移动设备上的图像分类、目标检测(如 SSD)等。
5. EfficientNet 系列
- 代表模型:
- EfficientNet B0~B7(基础版本)、EfficientNetV2(改进版)
- 特点:
- 使用 复合缩放方法(Compound Scaling) 同时调整网络的宽度、深度和分辨率,以实现计算效率和精度的平衡。
- 在保持较少参数的同时,达到或超过许多其他大型 CNN 模型的性能。
- EfficientNetV2 进一步优化了训练速度,适合大规模数据集。
- 不足:
- 结构较复杂,难以手动调整。
- 应用场景:
- 图像分类、迁移学习、特征提取、目标检测(如 YOLO 系列)。
6. DenseNet(Densely Connected Convolutional Network)系列
- 代表模型:
- DenseNet121、DenseNet169、DenseNet201
- 特点:
- 提出了 密集连接(Dense Connections),即在网络中每一层都连接到后续所有层。
- 特征复用性强,减少了参数量,并缓解了梯度消失问题。
- 网络较浅时也能获得较好的性能。
- 不足:
- 网络的内存占用较大,训练较慢。
- 应用场景:
- 图像分类、特征提取、医学图像分析。
7. YOLO(You Only Look Once)系列
- 代表模型:
- YOLOv1、YOLOv2、YOLOv3、YOLOv4、YOLOv5、YOLOv7、YOLOv8
- 特点:
- 虽然 YOLO 是目标检测框架,但其主干网络也可用于特征提取。
- 通过单次前向传播同时完成目标检测和分类,速度快,适合实时场景。
- YOLOv5 及之后版本进一步优化了轻量化和检测精度。
- 不足:
- 主干网络在特征提取方面不如专用分类模型精细。
- 应用场景:
- 目标检测、实时视频分析。
8. Vision Transformer(ViT)系列
虽然 Vision Transformer(ViT)并非传统 CNN,但其混合 CNN 的主干网络也可用于特征提取。
- 代表模型:
- ViT、DeiT、Swin Transformer
- 特点:
- 使用 Transformer 架构代替卷积操作,通过全局自注意力机制提取图像特征。
- Swin Transformer 结合了 CNN 和 Transformer 的优势,可处理多尺度特征。
- 不足:
- 计算复杂度较高,对硬件要求高。
- 应用场景:
- 图像分类、目标检测、语义分割。
9. NAS 系列(Neural Architecture Search)
通过神经架构搜索自动设计的 CNN 模型,性能优异且高效。
- 代表模型:
- NASNet、MnasNet、EfficientNet(由 NAS 衍生)。
- 特点:
- 自动搜索优化 CNN 结构,达到性能与效率的平衡。
- 结合 MobileNet 和 EfficientNet 的优点。
- 不足:
- 架构搜索过程需要大量计算资源。
- 应用场景:
- 图像分类、迁移学习。
10. ShuffleNet
- 特点:
- 专为移动设备设计,使用 分组卷积(Group Convolution) 和 通道混洗(Channel Shuffle) 技术优化计算效率。
- 比 MobileNet 更加轻量化。
- 不足:
- 性能略低于 MobileNet。
- 应用场景:
- 移动设备上的实时图像处理。
总结表:主流 CNN 模型对比
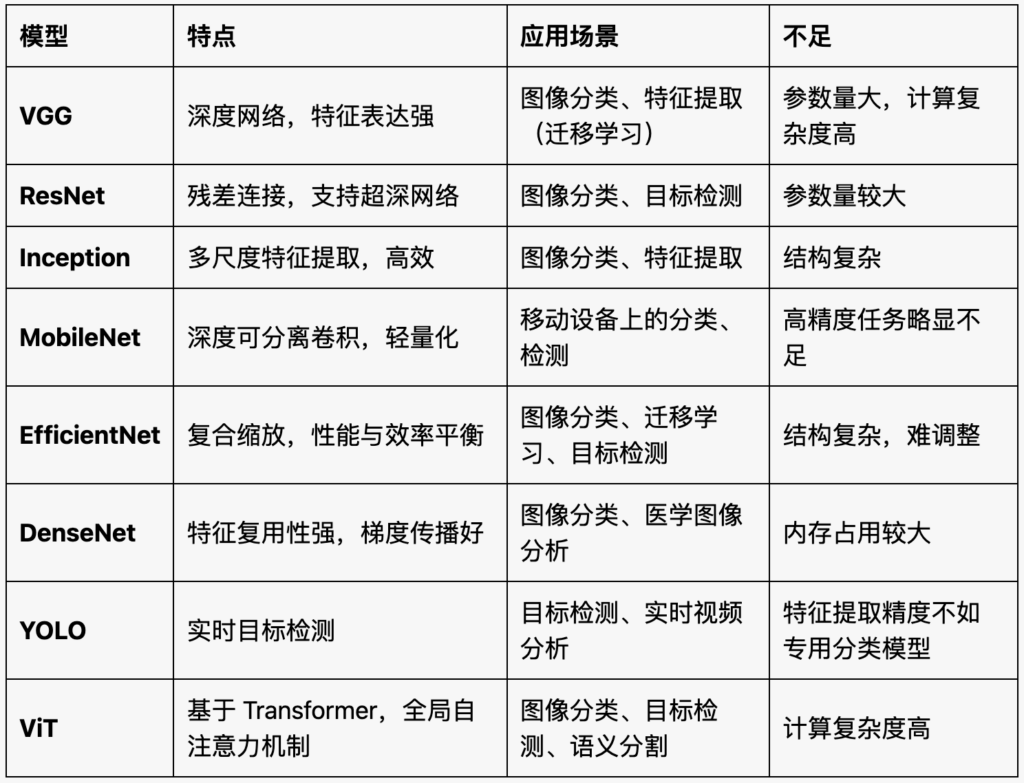
结论
目前 CNN 中自动提取图片特征的主流模型主要包括 ResNet、EfficientNet、DenseNet 和 MobileNet,它们在不同场景下各有优势。对于高性能需求,可以选择 ResNet 或 EfficientNet;对于移动端或嵌入式设备,可以选择 MobileNet 或 ShuffleNet。
