嵌入式应用使用云原生开发
2024年12月18日看到一个硬件设备的设计文档,在该设备里,居然使用了docker。这个设计真是超出我的意料。我印象中docker这种东东,都需要运行在专门的服务器环境里。现在硬件终端里也能运行docker,真是与时俱进。
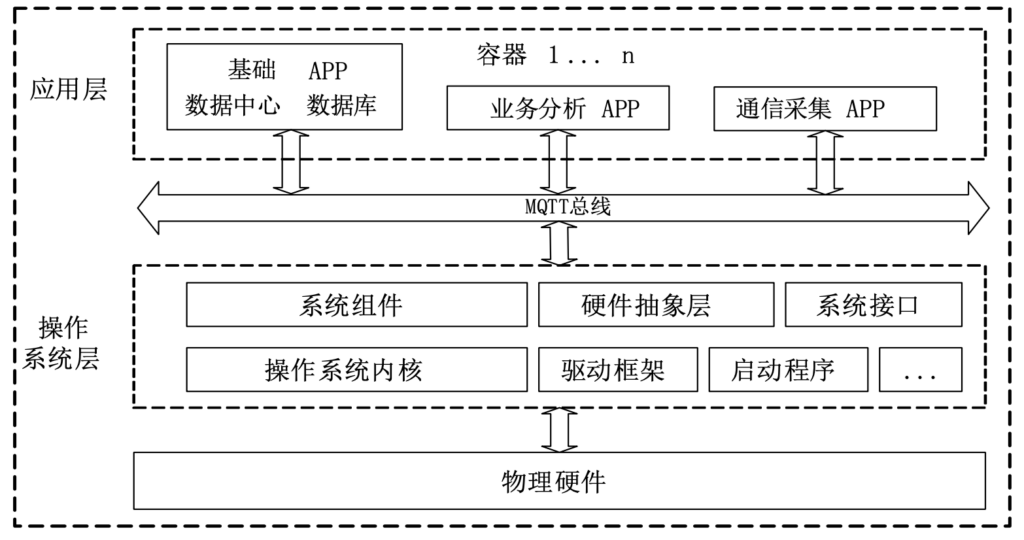
你看这个架构,清晰定义了docker容器所在的层次。业务分析软件,运行在docker里。允许自定义软件,以docker方式运行,从而实现环境隔离,这个设计理念蛮好的。
它对硬件性能的要求是这样的:主控 CPU 芯片应为全国产工业级芯片,CPU 应满足单芯双核以上(含双核),CPU 主频不低于 800MHz,运行内存应不低于 1GByte,数据存储器不低于 4GByte。可见这个设备的性能要求是不低的。
它对容器管理的要求如下:
- 应支持 4 个及以上容器数量,单个容器应支持部署多个应用软件;
- 应支持配置和修改容器资源,包括 CPU 核数量、内存、存储和接口,配置和修改容器资源应不影响已部署应用软件的运行;
- 应支持查询容器信息,包括容器列表、容器版本信息和容器运行状态;
- 应支持容器本地启动、停止、安装和卸载;
- 应支持容器本地和云平台远程升级;
- 应支持容器间通信和数据交互;
- 应支持物联管理平台远程管理网关容器管理功能。
我对嵌入式设备理解不深,但感觉这个要求就是一个小型版本的k8s了(详见我之前博客)。要在终端设备里维护一个小型k8s的稳定性,其实并不容易。
不过,使用docker的好处是可以带来环境隔离。应用部署在不同的docker里,使用隔离的计算、网络和存储资源,可以避免互相干扰。如果设备支持自定义应用程序,这个好处显而易见。
该设备对应用程序的要求也是支持自定义开发。说明如下:高级分析统计功能应支持独立开发,可根据现场实际需求选配,以 APP 形式实现,以满足新兴业务扩展需求。
设备的一个重要用途是数据采集。我从事大数据行业,看到这些采集指标,不由感叹采集容易做,标准定义难。在互联网公司,所谓的大数据,关键还是数据源头要管理好。采集做好了,大数据就成功一半。

数据采集后,经过清洗、存储,用途就很多。比如数仓、宽表、机器学习、统计建模等。哪怕是画最简单的统计图(如下表),对数据质量的要求也很高。原始数据定义清晰了,不代表采集上来的数据就是好的,这中间有数据治理的过程。

这些上报的数据,还有一个重要作用是故障统计,比如掉电、失压、失流、断相这种记录,对生产运维是至关重要的。既然能统计到故障,那么就可以触发告警,比如如下告警事件。

基于它这个硬件架构、软件需求,我感觉云原生的方式,竟然也适用于设备开发。这里完全可以用prometheus(详见我之前博客)来管理这些事件,含监控、告警、报表。而docker + prometheus在云原生里用得很多。
这个设备的核心功能还是数据采集、事件管理、故障告警、统计报表。这些功能在互联网的devops环境里见的比较多,但是在物联网设备里,居然也通过云原生来集成这些功能,确实是第一次见,作者在这里也表示长见识了。
