Spark常见查询范例
2025年3月19日如下是spark数据集合的schema:
scala> df.printSchema
root
|-- title: string (nullable = true)
|-- publisher: string (nullable = true)
|-- year: integer (nullable = true)
|-- author: string (nullable = true)
|-- country: string (nullable = true)
|-- price: double (nullable = true)
|-- category: string (nullable = true)
|-- edition: string (nullable = true)如下是数据集合的示例:
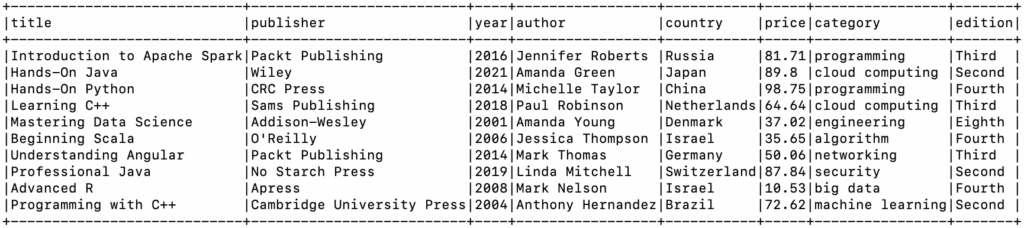
针对上述数据集合,常见的spark操作如下,覆盖聚合统计、分组排名、数据转换等。
基础查询操作
// 基础选择和过滤
df.select("title", "author", "price").show(5)
df.filter($"price" > 90).show(5)
df.filter($"category" === "programming").show(5)
// 排序
df.orderBy($"price".desc).show(5)
df.orderBy($"year".asc, $"price".desc).show(5)
聚合统计操作
// 基本统计
df.select(avg("price").as("平均价格"), min("price").as("最低价格"), max("price").as("最高价格")).show()
// 按分类统计
df.groupBy("category")
.agg(count("*").as("书籍数量"),
round(avg("price"), 2).as("平均价格"),
min("price").as("最低价格"),
max("price").as("最高价格"))
.orderBy($"书籍数量".desc)
.show()
// 按出版商和年份统计
df.groupBy("publisher", "year")
.count()
.orderBy($"publisher", $"year".desc)
.show()
// 统计每个国家的书籍数量及比例
val totalBooks = df.count()
df.groupBy("country")
.agg(count("*").as("书籍数量"),
round(count("*") * 100.0 / totalBooks, 2).as("占比百分比"))
.orderBy($"书籍数量".desc)
.show()
分组排名操作
// 使用窗口函数,计算每个分类中价格最高的书籍
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.functions._
val windowSpec = Window.partitionBy("category").orderBy($"price".desc)
df.withColumn("rank", dense_rank().over(windowSpec))
.filter($"rank" === 1)
.select("category", "title", "author", "price")
.orderBy("category")
.show()
// 计算每个出版商每年出版的书籍中价格排名前3的书籍
val publisherYearWindow = Window.partitionBy("publisher", "year").orderBy($"price".desc)
df.withColumn("price_rank", dense_rank().over(publisherYearWindow))
.filter($"price_rank" <= 3)
.select("publisher", "year", "title", "price", "price_rank")
.orderBy("publisher", "year", "price_rank")
.show()
复杂分析操作
// 计算每个分类的价格区间分布
df.withColumn("price_range",
when($"price" < 50, "低于50")
.when($"price" >= 50 && $"price" < 80, "50-80")
.when($"price" >= 80 && $"price" < 100, "80-100")
.otherwise("100以上"))
.groupBy("category", "price_range")
.count()
.orderBy("category", "price_range")
.show()
// 计算每年出版的书籍数量变化趋势
df.groupBy("year")
.count()
.orderBy("year")
.show()
// 各版本(edition)的平均价格比较
df.groupBy("edition")
.agg(count("*").as("书籍数量"), round(avg("price"), 2).as("平均价格"))
.orderBy($"平均价格".desc)
.show()
数据转换操作
// 为每本书添加一个价格评级列
df.withColumn("price_rating",
when($"price" <= 60, "便宜")
.when($"price" > 60 && $"price" <= 90, "中等")
.otherwise("昂贵"))
.select("title", "price", "price_rating")
.show()
// 计算每本书的价格与同类别平均价格的差异
val avgPriceByCategory = df.groupBy("category")
.agg(avg("price").as("avg_category_price"))
df.join(avgPriceByCategory, "category")
.withColumn("price_diff", round($"price" - $"avg_category_price", 2))
.withColumn("price_diff_percent", round(($"price" - $"avg_category_price") * 100 / $"avg_category_price", 2))
.select("title", "category", "price", "avg_category_price", "price_diff", "price_diff_percent")
.orderBy($"price_diff_percent".desc)
.show()
这些示例覆盖了从基础到高级的Spark SQL操作,包括选择、过滤、排序、聚合统计、窗口函数和数据转换等。您可以在Spark Shell中尝试这些操作,也可以根据需要修改这些示例来分析您的数据。
